בתמונה למעלה: מטה חברת סמסונג. מקור: ויקי
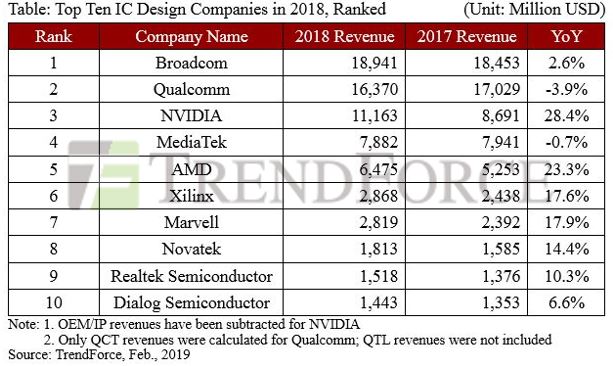
דרום קוריאה חשפה היום (ב') את אחת מתוכניות ההשקעה השאפתניות ביותר שנראו עד כה בתחום הבינה המלאכותית ותעשיית השבבים. במסגרת התוכנית, יושקעו כ-889 טריליון וון – כ-576 מיליארד דולר – בהקמת אקוסיסטם חדש של ייצור שבבים, אריזת שבבים, מרכזי נתונים ורובוטיקה, בניסיון לבסס את המדינה כאחת המובילות בעולם בעידן ה-AI.
התוכנית, שהוצגה על ידי נשיא דרום קוריאה, Lee Jae Myung, נשענת על שני התאגידים הגדולים במדינה – Samsung Electronics ו-SK Hynix – אשר יקימו ארבעה מפעלי ייצור שבבים (Fab) חדשים בדרום-מערב המדינה. שני מפעלים יוקמו על ידי סמסונג ושניים על ידי SK Hynix, במסגרת פרויקט ייצור שבבים בהיקף של כ-800 טריליון וון (כ-518 מיליארד דולר). בנוסף, יוקם מתחם מתקדם לאריזת שבבים סמוך לסיאול בהשקעה של 81 טריליון וון.
"עלינו להבטיח את מרכיבי הליבה של הבינה המלאכותית מהר יותר מכל מדינה אחרת", אמר הנשיא במהלך הצגת התוכנית. לדבריו, שלושת עמודי התווך של האסטרטגיה החדשה הם תעשיית השבבים, תחום ה-Physical AI – הכולל רובוטים ומערכות אוטונומיות – ותשתיות מחשוב ומרכזי נתונים.
במקביל להרחבת ייצור השבבים, הממשלה הציבה יעד להכפיל בתוך חמש שנים את תפוקת זיכרונות ה-DRAM – התחום שבו קוריאה כבר נחשבת למובילה עולמית. זיכרונות אלה מהווים את הבסיס גם לייצור שבבי HBM, רכיב קריטי במאיצי AI של חברות כמו NVIDIA.
התוכנית חורגת הרבה מעבר לייצור שבבים. הממשלה הכריזה על השקעות של כ-550 טריליון וון במרכזי נתונים עד 2029, עם יעד להגדיל את ההשקעות ליותר מ-1,000 טריליון וון עד 2035. במקביל, המדינה מבקשת להפוך עד 2030 למעצמה עולמית בתחום ה-Physical AI באמצעות שילוב רובוטים הומנואידיים בעשרה ענפי תעשייה והכשרת כ-10,000 מומחי AI ורובוטיקה.
גם החברות עצמן הציגו התחייבויות ארוכות טווח. סמסונג הודיעה כי בכוונתה להשקיע עד שנת 2040 כ-2,450 טריליון וון בדרום קוריאה, מהם כ-2,100 טריליון וון במתחמי השבבים המרכזיים במדינה. קבוצת SK, מצדה, הכריזה על השקעות של כ-1,100 טריליון וון בתחום השבבים וכ-1,000 טריליון וון נוספים במרכזי נתונים ל-AI, לצד הקדמת השלמת מפעל השבבים החדש שלה ביונגין לשנת 2033. יו"ר קבוצת SK, Chey Tae-won, הגדיר את חזון התוכנית במשפט אחד: "להפוך את קוריאה מ'צרכנית AI' ל'יצואנית אינטליגנציה'."
התוכנית משקפת את השינוי העמוק שעוברת הכלכלה הדרום-קוריאנית בעקבות מהפכת הבינה המלאכותית. בעוד שבעבר התבססה המדינה בעיקר על ייצור מוצרי אלקטרוניקה וזיכרונות, היא מנסה כעת לבנות שרשרת ערך מלאה – מייצור שבבים, דרך אריזתם ועד תשתיות מחשוב ורובוטיקה. הביקוש העולמי לשבבי AI כבר מזניק את היצוא הקוריאני, שעל פי תחזיות צפוי לרשום ביוני את קצב הצמיחה השנתי הגבוה ביותר זה קרוב לחמישה עשורים, בהובלת סמסונג ו-SK Hynix.





















")